Kubernetes
Редактировать на GitHubapiVersionЧто такое Namespace?🔹 Особенности Namespace🔹 Встроенные namespaceЧто такое Volume?🔹 Зачем нужен Volume🔹 ОсобенностиЧто такое ConfigMap?Что такое Secret?Что такое PersistentVolume (PV) и PersistentVolumeClaim (PVC)?🔹 Типы доступа PVC🔹 Схемы выделения PVЧто такое nodeSelector и nodeName?🔹 Пример использованияDaemonSet — зачем нужен и для чего обычно используется?🔹 Основные применения🔹 ОсобенностиЧто такое Taints и Tolerations?🔹 Виды taint-эффектовЧто такое Requests и Limits?🔹 CPU и память🔹 QoS классы Pod-овЧто такое Affinity и Anti-Affinity?🔹 Виды Affinity🔹 Пример YAMLЧто такое Helm?🔹 Основные понятия🔹 Зачем нужен🔹 Шаблоны в HelmЧто даёт Helm в Kubernetes?Если limit больше чем request и нет ресурсов на ноде — развернётся ли Pod?Через что реализованы сети в Kubernetes?🔹 Как это работает (на примере Flannel)🔹 Flannel🔹 CalicoЧто произойдёт при изменении image? Как будут докатываться изменения?🔹 Основные стратегии обновленийЧто такое Headless Service?🔹 Зачем нужен🔹 Пример манифестаПро сетевые взаимодействия в Kubernetes🔹 Уровни взаимодействияМинусы хранения секретов в Secret-ах KubernetesЧто можно редактировать (kubectl edit) в Pod-ах в процессе их работы, а что нельзя?🔹 Можно редактировать🔹 Нельзя редактироватьС помощью какого механизма идёт или перестаёт идти трафик в Kubernetes?Что такое HPA и как он работает?🔹 Как работаетЧем отличается вертикальное масштабирование от горизонтального?Какая функция в Kubernetes обеспечивается Linux Capabilities?Теоретические вопросы
Что такое kubernetes?
Это система управления кластерами контейнеров linux. Кубер может запускать и управлять контейнерами на большом количестве хостов. А также имеет возможность это всё размещать и реплицировать.
Какую проблему решает Kubernetes?
Ответ:
- Масштабирование и запуск контейнеров на большом количестве хостов.
- Балансировка нагрузки между контейнерами.
- Наличие высокоуровневого API для описания, группирования, размещения и балансировки контейнеров.
Какие задачи он решает:
- Автоматизация инфраструктуры (развёртывание приложений, обновления, откаты).
- Масштабирование приложений.
- Supervision — контроллеры следят за состоянием кластера и приводят его к описанной спецификации.
- Service discovery — автоматическое обнаружение сервисов.
- Логирование контейнеров.
- Мониторинг и сбор метрик.
- Поддержка CI/CD-процессов.
- Уменьшение vendor lock-in: Kubernetes абстрагирует железо и провайдера, мы работаем с его API как с «чёрным ящиком».
Что такое minikube?
Локальный кластер для знакомства с кубером, или для проверки каких-либо вещей.
Приведи пример проблемы, которую упрощает решение именно с использованием Kubernetes?
Ответ:
Представим, что у нас есть три машины с запущенными контейнерами.
Одна из машин выходит из строя или её нужно перезапустить. Контейнеры необходимо перенести на другие узлы. Без Kubernetes это потребует ручных действий.
Какие проблемы придётся решать вручную:
- Контейнеры могут быть связаны (общие данные или тесное взаимодействие) и должны находиться на одной ноде. Нужно перенести их вместе.
- Контейнеры могут не “поместиться” на одном узле — придётся решать, как их распределить по кластерам.
- При возврате ноды в строй — снова переносить контейнеры обратно или перераспределять их.
👉 Kubernetes автоматизирует все эти процессы: он сам следит за состоянием, перезапускает контейнеры, переносит их на доступные узлы и поддерживает заданные правила размещения.
В чем отличие StatefulSet от Deployment?
Ответ:
-
Deployment — ресурс Kubernetes для приложений без сохранения состояния.
- Реплики одинаковые и взаимозаменяемые.
- При использовании PVC все поды могут делить общий том (shared volume).
- Под легко пересоздаётся на другой ноде без привязки к конкретному хранилищу.
- Подходит для stateless-приложений (веб-сервисы, API, фронтенды).
-
StatefulSet — ресурс для приложений со состоянием.
- Каждая реплика получает собственное имя и собственный PVC (через volumeClaimTemplate).
- Сохраняется порядок запуска/удаления подов.
- Под «привязан» к своему диску: при падении ноды PVC остаётся за конкретной репликой.
- Подходит для баз данных, очередей, кластеров, где у каждой реплики есть уникальное состояние.
👉 StatefulSet используют там, где нужно гарантировать уникальное состояние и стабильную идентичность подов, в отличие от Deployment, где все реплики одинаковы.
Что такое StatefulSet?
Ответ:
StatefulSet — это контроллер Kubernetes для приложений со состоянием.
Он обеспечивает сохранение идентичности подов и их данных за пределами жизненного цикла контейнеров.
Особенности:
- Каждый под получает собственное имя (
<имя statefulset>-<номер пода>). - Каждый под имеет собственный PVC (через volumeClaimTemplate).
- Поды создаются и удаляются в строгом порядке (scale-up — по возрастанию, scale-down — в обратном порядке).
- При
SIGTERMпод может дольше завершаться, так как требуется корректное управление состоянием и volume-монтажами. - PVC обычно привязан к конкретной ноде. Чтобы обеспечить переносимость, можно использовать NAS, NFS или облачные CSI-драйверы.
Применение:
- StatefulSet используют для баз данных и очередей, где каждая реплика хранит собственное состояние.
- При увеличении числа реплик данные можно инициализировать от первой (master/primary).
- Подходит для кластерных систем (PostgreSQL, MySQL, Kafka, RabbitMQ, Zookeeper).
В чем отличие Deployment от ReplicaSet?
Ответ:
-
ReplicaSet — это контроллер, который гарантирует, что заданное количество подов всегда работает.
- Обеспечивает масштабирование и самовосстановление подов.
- Не умеет управлять версиями образов и выполнять обновления.
-
Deployment — это надстройка над ReplicaSet.
- Управляет ReplicaSet-ами и автоматизирует процесс обновления подов (rolling updates, rollbacks).
- При выкатывании новой версии Deployment создаёт новый ReplicaSet, постепенно масштабирует его вверх и уменьшает старый.
- Позволяет откатываться к предыдущей версии.
👉 Иными словами: ReplicaSet отвечает только за количество подов, а Deployment — за управление версиями и стратегиями обновлений.
Что такое Readiness, Liveness, Startup пробы, какое отличие?
Ответ (подробно):
-
Liveness Probe Проверяет, «жив» ли контейнер. Если проверка неуспешна — kubelet перезапускает контейнер. Применение: поймать ситуацию, когда процесс запущен, но приложение зависло или не отвечает.
-
Readiness Probe Проверяет, готов ли контейнер принимать трафик. Pod считается готовым только если все контейнеры в нём готовы. Применение: сервисы исключают поды из балансировки, пока они не в статусе Ready.
-
Startup Probe Проверяет, что приложение успешно стартовало. Пока она не успешна — Liveness и Readiness проверки отключены. Применение: медленно запускающиеся приложения (например, Java), чтобы избежать их убийства kubelet’ом до реального старта.
Ответ (проще):
Под — это не всегда «готовое приложение». Например, Java может подниматься минутами. Для этого и нужны пробы:
readinessProbe— можно ли пускать трафик на контейнер?livenessProbe— живо ли приложение внутри контейнера?startupProbe— успешно ли приложение вообще запустилось?
Пример readinessProbe:
readinessProbe:
httpGet:
path: /
port: 80
periodSeconds: 2 # частота проверки
failureThreshold: 3 # сколько ошибок допускается
successThreshold: 1 # сколько успешных проверок нужно
timeoutSeconds: 1 # таймаутВажно про livenessProbe:
- У неё есть параметр
initialDelaySeconds— через сколько секунд после старта контейнера начинать проверки. - Частая ошибка — поставить слишком маленькое значение, и kubelet будет перезапускать поды, думая, что они зависли.
- Иногда её советуют не использовать или применять осторожно.
👉 Таким образом, Readiness = готов к трафику, Liveness = живое ли приложение, Startup = запустилось ли оно вообще.
Хочешь, я добавлю сюда таблицу сравнения (Readiness vs Liveness vs Startup) для наглядности, как на собесе любят?
Что такое оператор в Kubernetes?
Ответ:
Оператор — это контроллер приложения, который упаковывает в себе знание о том, как развернуть, управлять и поддерживать конкретное приложение внутри Kubernetes.
Он расширяет API кластера за счёт Custom Resource Definitions (CRD) и автоматизирует жизненный цикл приложений.
Другими словами:
- Оператор — это под (или набор подов), который «следит», чтобы нужные ресурсы были развернуты, работали корректно и удалялись без ошибок.
- Он позволяет расширить возможности кластера за пределы встроенных объектов Kubernetes.
- Благодаря этому можно управлять сложными приложениями (БД, очередями, брокерами сообщений) как «родными» ресурсами Kubernetes.
Пример:
- PostgreSQL Operator — автоматизирует развёртывание кластера Postgres, настройку репликации, бэкапы и обновления.
- Prometheus Operator — управляет установкой Prometheus, Alertmanager и их конфигурацией.
В чем отличие CRD от Operator?
CRD (Custom Resource Definition)
- Расширяет API Kubernetes.
- Позволяет добавить новый тип ресурса (например,
PostgresCluster,RedisCache). - Сам по себе CRD только описывает схему ресурса и хранит его в etcd.
- Логики управления в нём нет.
Operator
- Это контроллер, который использует CRD.
- Следит за состоянием объектов кастомного ресурса и приводит их к нужному состоянию.
- В оператор «зашиваются» знания: как развернуть, обновить, починить приложение.
- Реализует цикл: Observe → Analyze → Act.
Пример:
- CRD
PostgresClusterописывает: хочу кластер Postgres с 3 репликами. - Operator (Postgres Operator) запускает StatefulSet-ы, PVC, настраивает репликацию, мониторит состояние и чинит рассинхрон.
👉 Итог: CRD = новый объект в API, Operator = логика, которая управляет этим объектом.
Что такое узел (нода) в Kubernetes?
Ответ:
Узел (node) — это физическая или виртуальная машина, которая является частью кластера Kubernetes.
Типы нод:
-
Master (control plane node)
Содержит управляющие и координирующие компоненты кластера: API server, etcd, scheduler, controller manager.
Отвечает за работу всего кластера. -
Worker node
На воркерах запускаются Pod’ы и приложения (рабочая нагрузка).
Каждый воркер содержит kubelet, kube-proxy и среду для контейнеров (container runtime).
Примечание:
В продакшене мастер и воркер обычно разделены на разные машины.
В Minikube или маленьких тестовых кластерах одна машина может выполнять обе роли.
Опиши архитектуру Kubernetes-кластера. Из чего он состоит?
Ответ:
Кластер Kubernetes состоит из мастер-нод (control plane) и воркер-нод (worker nodes).
🟦 Control plane (мастер-ноды)
В продакшене обычно используют 3+ мастер-ноды для отказоустойчивости и достижения кворума в etcd.
Нечётное количество мастеров помогает избежать split-brain.
Основные компоненты:
- API Server
Центральная точка входа. Принимает и обрабатывает все запросы к кластеру (REST API, kubectl). - Controller Manager
Набор контроллеров, следящих за состоянием кластера и приводящих его к описанному desired state. - Scheduler
Планировщик, который распределяет поды по узлам с учётом ресурсов и ограничений. - etcd
Распределённое key-value хранилище состояния кластера (источник истины).
🟩 Worker nodes (воркер-ноды)
На воркерах запускаются pod’ы и приложения. Количество воркеров зависит от нагрузки.
Компоненты воркер-ноды:
- kubelet
Агент, взаимодействующий с API server. Запускает и удаляет контейнеры через container runtime, репортит их статус. - kube-proxy
Управляет сетевыми правилами на узле.- Настраивает iptables или IPVS для балансировки трафика между подами.
- Выполняет DNAT (подмену ClusterIP на IP конкретного pod-а).
- Не занимается маршрутизацией между узлами — это делает CNI-плагин.
- Container runtime (Docker, containerd, CRI-O и др.)
Компонент, который непосредственно запускает контейнеры.
🟨 Дополнительно
- kubectl — клиент, который взаимодействует с API server.
- CNI-плагины (Calico, Flannel, Cilium) — обеспечивают сетевую связность между подами на разных нодах.
👉 Итог:
- Мастер-ноды управляют состоянием кластера.
- Воркер-ноды выполняют workload (приложения).
- Для отказоустойчивости: 3+ мастера и любое количество воркеров.
Что такое split-brain?
Ответ:
Split-brain («расщеплённый мозг») — это ситуация в распределённой системе, когда кластер распадается на несколько частей из-за сетевого разделения (network partition).
Каждая часть считает себя «основной» и продолжает принимать запросы.
Проблема:
- Несколько «лидеров» или «мастеров» одновременно.
- Нарушение консистентности данных (разные части кластера вносят изменения независимо).
- После восстановления сети данные могут конфликтовать или теряться.
Примеры:
- В Kubernetes: если нечётное количество мастеров не соблюдено, и кворум etcd не может быть достигнут.
- В RabbitMQ (старый mirrored queues): разные партиции думают, что они активные, и принимают разные данные.
- В СУБД (Postgres Patroni, Galera, Cassandra): две реплики становятся лидерами и пишут в базу независимо.
Защита от split-brain:
- Использование кворума (нечётное число нод).
- Алгоритмы консенсуса (Raft, Paxos).
- Настройка partition handling (например, pause_minority в RabbitMQ).
Расскажи подробнее про kube-proxy
Ответ:
kube-proxy — это сетевой компонент Kubernetes, который запускается на каждой воркер-ноде.
Он получает от API-сервера список сервисов и эндпоинтов и настраивает правила маршрутизации на узле.
Задача — чтобы запросы, пришедшие на сервис, доставлялись в нужный Pod.
⚙️ Режимы работы kube-proxy
- iptables — режим по умолчанию, строит iptables-правила для DNAT и балансировки.
- IPVS — более производительный режим, особенно при большом числе сервисов и эндпоинтов.
- userspace — устаревший режим, практически не используется.
🔄 Поведение при сбоях / удалении правил
Если вручную удалить все правила iptables на узле (iptables -F):
- Узел перестаёт принимать трафик (ClusterIP/NodePort → Pod).
kube-proxyпересоздаёт правила автоматически, обычно в течение ~30 секунд.- Восстановление регулируется параметрами:
--iptables-sync-period(по умолчанию ~30s) — интервал полной пересинхронизации.--iptables-min-sync-period(по умолчанию ~10s) — минимальный интервал реакции на изменения сервисов/эндпоинтов.
🛠️ Полезные параметры
--iptables-sync-period— задаёт частоту пересоздания правил; слишком большое значение = дольше недоступность при сбое.--iptables-min-sync-period— определяет, как быстро обновляются правила при изменениях сервисов.
🧩 Важные моменты
- Если
kube-proxyпадает или его правила удаляются, поды не получают трафик до восстановления. - Восстановление может занимать десятки секунд, что критично для latency-чувствительных приложений.
- При большом количестве сервисов и эндпоинтов лучше использовать режим IPVS.
Что такое Pod?
Ответ:
Pod — это минимальная единица развертывания в Kubernetes.
Он представляет собой запрос на запуск одного или нескольких контейнеров на одном узле.
Особенности:
- Контейнеры внутри Pod-а запускаются вместе и всегда на одном узле.
- Делят общий сетевой стек (IP-адрес, порты, loopback-интерфейс).
- Могут совместно использовать тома (volumes) для хранения данных.
- Имеют общий жизненный цикл: Pod создаётся, запускается и удаляется как единое целое.
Применение:
- Обычно Pod содержит один контейнер (наиболее частый кейс).
- Несколько контейнеров в Pod-е используют, если они должны работать рядом и тесно взаимодействовать (например, sidecar-контейнер для логирования или прокси).
В чем разница между Pod и контейнером?
Ответ:
-
Контейнер — это изолированный процесс с собственными ресурсами (CPU, память, файловая система, сеть).
Примеры: Docker, containerd. -
Pod — это минимальная единица Kubernetes, которая инкапсулирует один или несколько контейнеров.
Основные отличия:
- Pod управляется Kubernetes, контейнер — средой выполнения (Docker/containerd).
- Pod имеет свой IP-адрес и сетевой стек, общий для всех контейнеров внутри него.
- Контейнер сам по себе Kubernetes не запускает — он всегда работает внутри Pod-а.
- Поды позволяют группировать контейнеры, которые должны работать вместе (например, основной контейнер + sidecar).
👉 Итог: Контейнер = процесс, Pod = абстракция Kubernetes над контейнером(ами).
Как создается Pod? Какие компоненты задействуются при его создании?
Ответ:
-
Инициирование запроса
- Пользователь выполняет команду
kubectl apply -f pod.yamlили отправляет запрос к API. - Запрос попадает в kube-apiserver.
- Пользователь выполняет команду
-
Обработка на уровне control plane
- API Server аутентифицирует и авторизует запрос.
- Валидирует манифест Pod-а.
- Сохраняет описание Pod-а в
etcd(центральное хранилище состояния кластера).
👉 На этом этапе Pod ещё не запущен, он существует только как запись в etcd.
-
Планирование
- Scheduler периодически опрашивает API Server.
- Находит Pod-ы без привязки к ноде.
- Выбирает подходящий воркер-узел с учётом ресурсов и ограничений.
- Записывает решение в API Server (binding Pod → Node).
-
Запуск на воркер-узле
- kubelet на выбранной ноде получает задание от API Server.
- Обращается к Container Runtime Interface (CRI) (например, containerd или CRI-O).
- CRI скачивает образ (если нужно) и запускает контейнер(ы) Pod-а.
-
Сетевые настройки
- kubelet вызывает CNI-плагин (Calico, Flannel и др.) для настройки сетевого интерфейса Pod-а и выдачи ему IP-адреса.
- kube-proxy обновляет правила маршрутизации и балансировки для доступа к Pod-у.
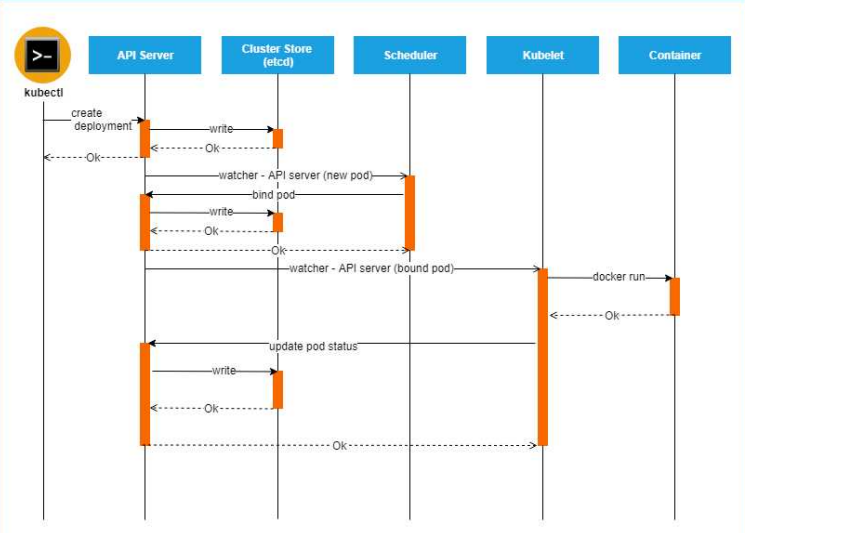
Итог:
kubectl → kube-apiserver → etcd → scheduler → kubelet → CRI → CNI → kube-proxy- Каждый шаг отвечает за: сохранение состояния → выбор узла → запуск контейнеров → сетевую связность.
Может ли Pod запуститься на двух разных узлах?
Ответ:
Нет.
Pod всегда запускается только на одной конкретной ноде, выбранной Scheduler-ом.
У Pod-а есть поле spec.nodeName, которое указывает, на какой узел он назначен.
Если нужно несколько копий приложения на разных узлах, Kubernetes создаёт несколько Pod-ов через ReplicaSet, Deployment или StatefulSet.
👉 То есть один Pod ≠ несколько узлов. Для распределения нагрузки используют контроллеры, которые создают несколько Pod-ов на разных воркерах.
Что такое ReplicaSet?
Ответ:
ReplicaSet — это контроллер Kubernetes, следующий уровень абстракции над Pod-ами.
Он гарантирует, что всегда будет запущено заданное количество Pod-ов.
ReplicaSet может запускать Pod-ы на разных узлах кластера, поддерживая их количество в состоянии Desired.
🔹 Основные моменты
- В манифесте задаём поле
replicas. - ReplicaSet использует
selectorдля поиска и управления Pod-ами. - Pod-ы создаются по шаблону
template. - Если Pod удаляется или падает, ReplicaSet создаёт новый.
- Важно: ReplicaSet не управляет обновлениями версий образов. Если поменять image в YAML, старые Pod-ы не обновятся, пока их вручную не удалить. Для обновлений используют Deployment.
🔹 Пример манифеста ReplicaSet
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-replicaset
spec:
replicas: 2 # сколько Pod-ов нужно поддерживать
selector:
matchLabels:
app: my-app
template: # шаблон Pod-а
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx:1.12
ports:
- containerPort: 80🔹 Пример вывода
kubectl get replicasets -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
my-replicaset 2 2 2 10m nginx nginx:1.12 app=my-app- DESIRED — сколько реплик должно быть.
- CURRENT — сколько запущено.
- READY — сколько готовы к работе.
- AGE — возраст ReplicaSet.
- IMAGES — какой образ используется.
- SELECTOR — по каким меткам ReplicaSet ищет Pod-ы.
📌 Итог:
ReplicaSet отвечает за количество Pod-ов, а Deployment — за их версии и обновления.
Что такое Deployment?
Ответ:
Deployment (развертывание) — это контроллер Kubernetes, который управляет Pod-ами через ReplicaSet и позволяет выполнять управляемые обновления приложений.
Он похож на ReplicaSet, но добавляет возможности: обновления, откаты и стратегию выкатывания новых версий.
🔹 Пример манифеста Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 2 # количество контейнеров
strategy:
type: Recreate # стратегия обновления
selector:
matchLabels:
app: my-app
template: # шаблон Pod-а
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx:1.12
ports:
- containerPort: 80🔹 Стратегии обновления
- Recreate — пересоздание Pod-ов: старые удаляются, новые создаются. Downtime возможен.
- RollingUpdate (по умолчанию) — постепенное обновление. Поддерживается настройками:
maxSurge— сколько Pod-ов можно добавить сверх нужного числа.maxUnavailable— сколько Pod-ов может быть временно недоступно.
- Старые ReplicaSet-ы сохраняются (как история версий), но остаются пустыми.
🔹 Пример вывода
kubectl get pods
NAME READY STATUS RESTARTS AGE
my-deployment-c4c8f45fc-ltckj 1/1 Running 0 4s
my-deployment-c4c8f45fc-qvp6w 1/1 Running 0 4s
kubectl get replicasets
NAME DESIRED CURRENT READY AGE
my-deployment-c4c8f45fc 2 2 2 17sDeployment создаёт ReplicaSet, а тот уже управляет Pod-ами.
Имя ReplicaSet = имя Deployment + хэш.
Имя Pod = имя ReplicaSet + уникальный идентификатор.
📌 Итог:
ReplicaSet следит только за количеством Pod-ов, а Deployment позволяет обновлять их версии и управлять стратегией релиза.
Что такое Service?
Ответ:
Service — это абстракция Kubernetes, которая обеспечивает стабильный сетевой доступ к Pod-ам.
Pod-ы эфемерны: их IP-адреса могут меняться при перезапуске. Service решает эту проблему, создавая постоянную точку входа и балансировку трафика.
🔹 Как работает Service
- Service описывается манифестом и привязывается к Pod-ам через label selector.
- kube-proxy получает список эндпоинтов (IP-адресов Pod-ов) от API и настраивает правила (iptables/IPVS) для перенаправления трафика.
- DNS внутри кластера (CoreDNS) регистрирует имя сервиса (
my-service.default.svc.cluster.local), по которому можно обратиться.
🔹 Типы Service и на чём основаны
-
ClusterIP (default)
- Создаёт виртуальный IP (ClusterIP), доступный только внутри кластера.
- kube-proxy настраивает iptables/IPVS правила для перенаправления.
- Используется для взаимодействия сервисов внутри кластера.
- Основа: DNAT через iptables/IPVS.
-
NodePort
- Открывает порт на каждой ноде кластера (обычно в диапазоне 30000–32767).
- Доступ извне кластера осуществляется через
<NodeIP>:<NodePort>. - kube-proxy перенаправляет трафик с этого порта на Pod-ы.
- Основа: iptables правила DNAT, указывающие с NodePort → ClusterIP → Pod.
-
LoadBalancer
- Используется в облаках (AWS ELB, GCP LB, Azure LB).
- Автоматически создаёт внешний балансировщик у провайдера и привязывает его к NodePort/ClusterIP.
- Внешний IP балансировщика становится точкой входа.
- Основа: NodePort + интеграция с облачным API.
-
ExternalName
- Не создаёт правил маршрутизации.
- Вместо этого возвращает CNAME-запись на внешний DNS-адрес.
- Пример:
external-service.default.svc.cluster.local → db.example.com. - Основа: чисто DNS (CoreDNS), без kube-proxy.
🔹 Примеры YAML
ClusterIP (default):
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80 # порт сервиса
targetPort: 8080 # порт контейнера
type: ClusterIPNodePort:
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
nodePort: 30080LoadBalancer (облако):
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080ExternalName:
spec:
type: ExternalName
externalName: db.example.com📌 Итог:
- ClusterIP — только внутри кластера.
- NodePort — доступ извне через порт на ноде.
- LoadBalancer — облачный балансировщик для внешнего доступа.
- ExternalName — проксирует на внешний DNS.
Все типы, кроме ExternalName, используют kube-proxy (iptables или IPVS) для маршрутизации.
Что такое Ingress?
Ответ:
Ingress — это объект Kubernetes, который управляет входящим HTTP/HTTPS-трафиком и маршрутизирует его к сервисам внутри кластера.
Он не является типом Service, но тесно связан с сетевым доступом извне.
Особенности:
- Работает как reverse-proxy (часто сравнивают с Nginx).
- Позволяет маршрутизировать трафик по:
- host (например,
app.example.com → service1,api.example.com → service2) - path (например,
/app → service1,/api → service2)
- host (например,
- Может терминировать TLS (обеспечивать HTTPS).
- Ingress Controller (Nginx, Traefik, HAProxy, Istio ingress gateway и др.) реализует работу Ingress.
Важно:
- Ingress направляет трафик напрямую на Pod Endpoints, минуя «лишний хоп» через ClusterIP.
- Без Ingress для доступа снаружи пришлось бы использовать
NodePortилиLoadBalancerдля каждого сервиса.
Пример манифеста Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
spec:
rules:
- host: app.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-service
port:
number: 80📌 Итог:
Ingress = абстракция для управления внешним HTTP(S)-трафиком: маршрутизация, балансировка, TLS.
Он работает поверх сервисов, но даёт более гибкий способ публиковать приложения.
Что такое Job?
Ответ:
Job — это объект Kubernetes для запуска одноразовых задач.
Он создаёт один или несколько Pod-ов и ждёт их успешного завершения.
Если Pod завершается с ошибкой, Job запускает новые, пока не будет достигнуто заданное количество успешных выполнений.
🔹 Типовые примеры использования
- Запуск тестов.
- Применение миграций базы данных.
- Выполнение одноразовых скриптов (batch-задач).
🔹 Важные параметры Job
- completions — сколько успешных выполнений должно быть достигнуто.
- parallelism — сколько Pod-ов может запускаться параллельно (если
1, то выполняются по очереди). - backoffLimit — максимальное число повторных запусков при ошибках.
- activeDeadlineSeconds — максимальное время выполнения Job.
- ttlSecondsAfterFinished — сколько хранить информацию о завершённой Job (например, чтобы успеть посмотреть логи).
- restartPolicy — политика рестартов контейнеров внутри Pod-ов. Обычно =
Never.
🔹 Пример манифеста Job
apiVersion: batch/v1
kind: Job
metadata:
name: example-job
spec:
completions: 3 # сколько успешных запусков нужно
parallelism: 2 # сколько подов можно запускать одновременно
backoffLimit: 4 # число ретраев при ошибках
activeDeadlineSeconds: 60 # ограничение по времени (сек)
ttlSecondsAfterFinished: 30 # хранить объект ещё 30 сек после завершения
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never📌 Итог:
Job = одноразовая задача в Kubernetes.
Он гарантирует выполнение и перезапускает Pod-ы при сбоях до достижения заданного результата.
Что такое CronJob?
Ответ:
CronJob — это объект Kubernetes, который автоматически запускает Job по расписанию.
Расписание задаётся в формате cron (* * * * *).
Каждый запуск CronJob создаёт новый Job, который в свою очередь запускает Pod-ы.
🔹 Применение
- Регулярные рассылки писем или уведомлений.
- Автоматические бэкапы.
- Запуск периодических скриптов в часы наименьшей нагрузки.
🔹 Важные параметры CronJob
- schedule — расписание в cron-формате.
- concurrencyPolicy — как вести себя при наложении задач:
Allow(по умолчанию) — разрешает параллельное выполнение.Forbid— новое задание не стартует, пока не завершилось предыдущее.Replace— новое задание заменяет текущее.
- startingDeadlineSeconds — сколько секунд даётся на запуск пропущенного задания.
- successfulJobsHistoryLimit / failedJobsHistoryLimit — сколько хранить успешных/неудачных Job в истории.
🔹 Пример манифеста CronJob
apiVersion: batch/v1
kind: CronJob
metadata:
name: example-cronjob
spec:
schedule: "0 2 * * *" # запуск каждый день в 02:00
concurrencyPolicy: Forbid # не запускать, если предыдущее ещё работает
jobTemplate:
spec:
template:
spec:
containers:
- name: backup
image: busybox
command: ["sh", "-c", "echo Backup started; sleep 10; echo Backup finished"]
restartPolicy: OnFailure📌 Итог:
- Job = одноразовая задача.
- CronJob = Job, запускаемый по расписанию.
Что означает версия API (apiVersion)?
Ответ:
Поле apiVersion в манифестах Kubernetes указывает, к какой версии API относится объект.
Разные ресурсы (Pod, Deployment, Ingress и т. д.) могут находиться в разных стадиях развития API.
🔹 Типы версий
-
Alpha (
v1alpha1,apps/v1alpha1)- Включены не по умолчанию.
- Могут содержать баги, поддержка может быть прекращена в любой момент.
- Совместимость с будущими версиями не гарантируется.
- ❌ Не рекомендуется для продакшена.
-
Beta (
v1beta1,extensions/v1beta1)- Включены по умолчанию.
- Хорошо протестированы.
- Гарантия поддержки есть, но возможны изменения в семантике.
- При изменениях предоставляется инструкция по миграции.
- ⚠️ Можно использовать для dev/test, но осторожно в продакшене.
-
Stable (например,
v1,apps/v1)- Считаются стабильными и готовыми к использованию в продакшене.
- Поддерживаются в будущем, совместимы по API.
- ✅ Рекомендуемый вариант для production.
🔹 Примеры apiVersion
v1— базовые ресурсы (Pod, Service, ConfigMap).apps/v1— контроллеры (Deployment, StatefulSet, DaemonSet, ReplicaSet).batch/v1— задачи (Job, CronJob).networking.k8s.io/v1— сетевые объекты (Ingress, NetworkPolicy).extensions/v1beta1— устаревший путь, раньше содержал Ingress/Deployment.
📌 Итог:
alpha= экспериментально, выключено по умолчанию.beta= включено, тестировать можно, осторожно использовать.stable= готово к продакшену.
Что такое Namespace?
Ответ:
Namespace (пространство имён) — это способ логического разделения ресурсов внутри кластера Kubernetes между пользователями, проектами или средами.
🔹 Особенности Namespace
- Все имена ресурсов должны быть уникальными в пределах одного namespace.
- Ресурс может принадлежать только одному namespace.
- Namespace не могут быть вложенными.
🔹 Встроенные namespace
- default — пространство имён по умолчанию, если не указано иное.
- kube-system — системные ресурсы и служебные объекты Kubernetes.
- kube-public — автоматически создаваемое пространство имён, доступное для чтения всеми пользователями. Обычно используется для публичных ресурсов.
- (начиная с новых версий) kube-node-lease — хранит объекты lease, которые используются для heartbeat нод.
📌 Итог:
Namespace = «виртуальный кластер внутри кластера», который позволяет изолировать ресурсы и управлять доступом.
Что такое Volume?
Ответ:
Volume — это абстракция Kubernetes для организации файлового хранилища внутри Pod-а.
🔹 Зачем нужен Volume
- Файловая система контейнера живёт только пока работает контейнер. При удалении или перезапуске данные теряются.
- Несколько контейнеров в одном Pod-е могут нуждаться в общем доступе к файлам.
- Нужна возможность подключать конфигурации или секреты как файлы.
- Volume изолирует приложение от конкретной технологии хранения данных (локальная FS, NFS, облачное хранилище).
🔹 Особенности
- Volume живёт столько же, сколько Pod. Когда Pod удаляется — Volume удаляется тоже (кроме PersistentVolume).
- Контейнеры внутри Pod-а могут монтировать Volume в разные директории.
- Существует много типов Volume:
emptyDir— временное хранилище на узле, живёт пока работает Pod.hostPath— доступ к директории/файлам на узле.configMap/secret— монтирование конфигураций и секретов.persistentVolumeClaim— привязка к долговременному хранилищу (PersistentVolume).
📌 Итог:
Volume = способ сделать данные в Pod-е доступными и сохранить их дольше жизни одного контейнера.
Что такое ConfigMap?
Ответ:
ConfigMap — это объект Kubernetes для хранения неконфиденциальных данных в формате ключ–значение.
Использование в Pod:
- как переменные окружения,
- как файлы через volume,
- как параметры запуска контейнера.
📌 Итог: ConfigMap = способ передавать конфигурацию Pod-ам без вшивания её в образ.
Что такое Secret?
Ответ:
Secret — это объект Kubernetes для хранения конфиденциальных данных (пароли, токены, ключи).
Он позволяет не вшивать чувствительные данные в Pod-ы или образы контейнеров.
Использование:
- как переменные окружения,
- как файлы через volume,
- для авторизации (например, при загрузке образов из приватного registry).
📌 Итог: Secret = безопасное хранение и передача чувствительных данных Pod-ам.
Что такое PersistentVolume (PV) и PersistentVolumeClaim (PVC)?
Ответ:
-
PersistentVolume (PV) — объект Kubernetes, представляющий ресурс хранилища в кластере.
Аналог узла, только вместо CPU/RAM предоставляет дисковые тома.
Примеры: локальный диск, NFS, CephFS, облачные диски (AWS EBS, GCE PD). -
PersistentVolumeClaim (PVC) — это запрос от Pod-а к PV.
Указывает, какой объём и тип доступа к хранилищу нужны.
Kubernetes сопоставляет PVC с подходящим PV.
🔹 Типы доступа PVC
- ReadWriteOnce (RWO) — том доступен на чтение/запись только одному Pod-у.
- ReadOnlyMany (ROX) — том доступен многим Pod-ам только для чтения.
- ReadWriteMany (RWX) — том доступен многим Pod-ам для чтения и записи.
🔹 Схемы выделения PV
1. Статическое
- Админ заранее создаёт набор PV фиксированных размеров.
- PVC запрашивает ресурс → Kubernetes ищет подходящий PV.
- Если запрос меньше доступного, Pod получит больший PV (например, запрос на 5 ГБ → доступен только PV на 100 ГБ).
- Минус: не всегда оптимально используется хранилище.
2. Динамическое
- Админ создаёт StorageClass, описывающий тип хранилища.
- PVC → автоматически создаётся PV нужного размера.
- Решает проблему неэффективного использования ресурсов.
📌 Итог:
- PV = объект-хранилище.
- PVC = запрос на это хранилище.
- Static provisioning = PV создаются заранее.
- Dynamic provisioning = PV создаются автоматически по запросу PVC через StorageClass.
Что такое nodeSelector и nodeName?
Ответ:
Это механизмы управления тем, на какой ноде будет запущен Pod.
-
nodeSelector — выбирает ноду по меткам.
В Pod-е указываются key:value метки, и Pod будет назначен только на те узлы, у которых есть такие же метки. -
nodeName — прямое указание имени ноды.
Pod будет запущен именно на этой конкретной ноде (если она доступна).
🔹 Пример использования
spec:
nodeSelector:
disktype: ssd # Pod запустится только на узлах с меткой disktype=ssd
nodeName: kube-01 # Явно указанный узел для Pod-а📌 Итог:
nodeSelector= фильтрация по меткам (гибко, рекомендуется).nodeName= жёсткая привязка к конкретной ноде (не рекомендуется для production).
DaemonSet — зачем нужен и для чего обычно используется?
Ответ:
DaemonSet — это контроллер Kubernetes, который гарантирует, что на каждой ноде (или на выбранной группе нод) будет запущен ровно один Pod.
Для него не нужен Scheduler — Pod автоматически резервируется на каждой ноде.
🔹 Основные применения
- Сбор логов (например,
fluentd,logstash) с каждой ноды. - Сбор метрик и мониторинг (
node-exporter,datadog-agent,prometheus-node-exporter). - Сетевые агенты или плагины (
calico-node,weave,cilium-agent). - Управление доступом/секьюрити агенты (например,
falco).
🔹 Особенности
- Pod запускается на всех нодах, включая новые, которые добавляются в кластер.
- Можно ограничить запуск только на определённых нодах с помощью
nodeSelector,nodeAffinity,taints/tolerations. - Для демонсетов не нужен планировщик (scheduler), так как назначение идёт напрямую.
📌 Итог:
DaemonSet = «один Pod на каждую ноду» → обычно используют для агентов логирования, мониторинга, сетевых и системных сервисов.
Что такое Taints и Tolerations?
Ответ:
- Taint — «метка-блокировка» для ноды.
Она указывает, что на эту ноду нельзя запускать Pod-ы без соответствующей «сопротивляемости». - Toleration — настройка в Pod-е, которая позволяет ему «терпеть» определённый taint и всё же запускаться на такой ноде.
👉 Смысл: taints задают где нельзя запускать, а tolerations — какие Pod-ы могут обойти ограничение.
🔹 Виды taint-эффектов
- NoSchedule — Pod-ы без соответствующих tolerations не будут запускаться на ноде. Уже работающие Pod-ы не трогаются.
- PreferNoSchedule — «мягкое ограничение»: по возможности не запускать Pod-ы без tolerations на этой ноде, но не запрещено.
- NoExecute — не только блокирует новые Pod-ы, но и удаляет с ноды уже работающие Pod-ы без нужных tolerations.
📌 Итог:
- Taints = задаём правила для ноды: «кого не пускать».
- Tolerations = настройка Pod-а: «я могу работать на таких нодах».
Что такое Requests и Limits?
Ответ:
В спецификации Pod-а можно указать:
- Requests — гарантированное количество ресурсов (CPU, память), которое Pod получит. Используется при планировании (scheduler).
- Limits — максимальное количество ресурсов, которое Pod может использовать.
🔹 CPU и память
cpu: 50m→ 50 милиCPU (0.05 от одного ядра).memory: 128Mi→ 128 мегабайт памяти.- Если контейнер превысил limit по CPU → будет ограничен планировщиком (throttling).
- Если превысил limit по памяти → контейнер будет убит (OOMKilled).
🔹 QoS классы Pod-ов
Качество обслуживания (Quality of Service) зависит от комбинации requests и limits:
-
Guaranteed —
requests = limitsдля всех контейнеров.
Pod гарантированно получит указанные ресурсы. -
Burstable —
requests < limits.
Pod получает минимум по requests, может использовать больше до limits, если есть ресурсы. -
BestEffort — не указаны
requestsиlimits.
Pod получает ресурсы только если они есть, и первым будет выгружен при нехватке.
📌 Итог:
- Requests = сколько Pod «просит» (гарантия).
- Limits = жёсткий максимум.
- QoS = класс качества обслуживания, влияющий на приоритет при нехватке ресурсов.
Что такое Affinity и Anti-Affinity?
Ответ:
Affinity/Anti-Affinity — это механизмы управления расписанием Pod-ов (scheduling) в Kubernetes.
Они позволяют задать правила, где Pod-ы должны или не должны запускаться — с учётом меток нод и других Pod-ов.
🔹 Виды Affinity
- Node Affinity — правила выбора нод (аналог
nodeSelector, но гибче). - Pod Affinity — Pod-ы должны располагаться вместе (например, на одной ноде/зоне).
- Pod Anti-Affinity — Pod-ы должны быть распределены по разным нодам/зонам.
🔹 Пример YAML
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: NotIn
values: ["hdd"] # ноды не с HDD
- key: memory
operator: Gt
values: ["8Gi"] # минимум 8ГБ RAM
- key: gpu
operator: Exists # наличие GPU
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["web-app"] # Pod-ы web-app должны быть на разных нодах
topologyKey: kubernetes.io/hostname
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values: ["s1"] # Pod должен находиться с Pod-ами security=s1
topologyKey: kubernetes.io/hostname📌 Итог:
- Node Affinity = требования к нодам.
- Pod Affinity = Pod-ы вместе.
- Pod Anti-Affinity = Pod-ы распределены.
Что такое Helm?
Ответ:
Helm — это пакетный менеджер для Kubernetes и одновременно шаблонизатор манифестов.
Он упрощает установку и управление приложениями в кластере.
🔹 Основные понятия
- Chart — пакет Helm, включающий YAML-манифесты и шаблоны (
.yaml,.tpl). - Release — установленный экземпляр Chart-а в кластере.
🔹 Зачем нужен
- Упрощает деплой сложных приложений (состоящих из множества манифестов).
- Позволяет переиспользовать один и тот же Chart для разных окружений (dev, stage, prod) с разными values.
- Поддерживает обновления и откаты приложений.
🔹 Шаблоны в Helm
- Файлы с расширением
_.tplсодержат функции-шаблоны, определяемые черезdefine. - Эти функции можно вызывать в других манифестах с помощью
include. - Обычно такие шаблоны используют для генерации:
- labels,
- имён ресурсов,
- общих параметров.
Что даёт Helm в Kubernetes?
Ответ:
- Версионирование манифестов и чартов.
- Шаблонизация ресурсов (одни и те же манифесты можно адаптировать под разные окружения).
- Удобное развертывание приложений и инфраструктуры на разных контурах (dev, stage, prod).
- Контроль версий релизов — легко обновлять и откатывать изменения.
- Управление зависимостями:
- в
Chart.yamlилиrequirements.yamlможно указать, от каких чартов зависит приложение; - командой
helm dependency updateподтягиваются все необходимые зависимости перед установкой.
- в
📌 Итог:
Helm = «apt/yum для Kubernetes» + мощный шаблонизатор.
Он даёт версионирование, удобное управление окружениями и зависимостями, а также делает деплой инфраструктуры и приложений более управляемым.
Если limit больше чем request и нет ресурсов на ноде — развернётся ли Pod?
Ответ:
Да.
Scheduler размещает Pod на основе requests — это минимально гарантированные ресурсы.
Если на ноде хватает ресурсов под requests, Pod будет запущен, даже если его limit выше.
Но:
- Если Pod начнёт потреблять ресурсов больше, чем доступно на ноде, ядро/кубернетес могут его убить (OOMKilled).
- Такая ситуация называется overcommit — когда суммарные limits превышают реальные ресурсы ноды.
📌 Итог: Pod развернётся, но при превышении доступных ресурсов может быть выгружен.
Через что реализованы сети в Kubernetes?
Ответ:
Kubernetes реализует сеть через плагины CNI (Container Networking Interface).
CNI — это стандарт взаимодействия kubelet с сетевыми плагинами.
Наиболее распространённые реализации: Flannel, Calico, Weave, Cilium.
🔹 Как это работает (на примере Flannel)
- kube-controller-manager назначает каждому узлу свой
podCIDR. - Pod-ы на узле получают IP-адреса из этого диапазона. Подсети разных нод не пересекаются → каждый Pod имеет уникальный IP.
- При создании Pod-а kubelet вызывает CRI (например, containerd).
- CRI вызывает CNI-плагин (Flannel, Calico и др.), который настраивает сеть и назначает IP.
- В итоге Pod получает IP-адрес, доступный в пределах всего кластера.
🔹 Flannel
- Простая реализация сетевой связности.
- Работает через оверлей (VXLAN).
- Подходит для базовых сценариев, когда нужна только связность.
🔹 Calico
- Более сложный и функциональный плагин.
- Поддерживает:
- NetworkPolicy (ограничение трафика между Pod-ами).
- Маршрутизацию без оверлея (BGP).
- Используется чаще в продакшене, где нужны политики безопасности.
📌 Итог:
Сети в Kubernetes строятся через CNI-плагины.
- Flannel → простая связность (overlay).
- Calico → связность + network policies + BGP.
Что произойдёт при изменении image? Как будут докатываться изменения?
Ответ:
При изменении образа (image) в манифесте Deployment Kubernetes запускает процесс обновления Pod-ов.
Это делается через стратегию обновления, заданную в Deployment.
🔹 Основные стратегии обновлений
-
RollingUpdate (по умолчанию)
- Новые Pod-ы создаются постепенно.
- Старые Pod-ы удаляются только после того, как новые стали
Ready. - Процесс контролируется параметрами:
maxSurge— сколько дополнительных Pod-ов можно создать сверх нужного.maxUnavailable— сколько Pod-ов может быть временно недоступно.
-
Recreate
- Все старые Pod-ы удаляются сразу.
- Затем создаются новые Pod-ы.
- Может привести к простою.
📌 Итог:
После изменения image Kubernetes создаёт новые Pod-ы по стратегии (RollingUpdate/Recreate).
Когда новые Pod-ы проходят health-check (readinessProbe), старые удаляются.
Что такое Headless Service?
Ответ:
Headless Service — это Service без собственного ClusterIP (clusterIP: None).
Он не балансирует трафик, а возвращает список IP-адресов Pod-ов, подходящих под селектор.
DNS-запрос к такому сервису возвращает A-записи для каждого Pod-а.
🔹 Зачем нужен
- Когда требуется обращаться к Pod-ам напрямую, без балансировки.
- Для приложений, где важна идентичность Pod-а (например, базы данных, StatefulSet).
- Для сервисов, которые сами реализуют логику балансировки/репликации.
🔹 Пример манифеста
apiVersion: v1
kind: Service
metadata:
name: my-headless-service
spec:
selector:
app: web-app
clusterIP: None # ключевая настройка
ports:
- port: 80
targetPort: 8080🔹 Пример взаимодействия
# Список Pod-ов по селектору
kubectl get pods -l app=web-app -o jsonpath='{.items[*].metadata.name}'
# Запрос к конкретному Pod-у через Headless Service
curl http://<pod-name>.my-headless-service.default.svc.cluster.local
# Запрос к сервису (вернёт список IP подов)
curl http://my-headless-service.default.svc.cluster.local:80Через обычный Service (с ClusterIP) поведение будет иное — трафик попадёт на рандомный Pod через балансировку:
curl http://common-service📌 Итог:
Headless Service = Service без ClusterIP, который раскрывает Pod-ы напрямую через DNS-записи.
Используется в StatefulSet и там, где нужно управлять балансировкой самостоятельно.
Про сетевые взаимодействия в Kubernetes
Подробнее можно почитать здесь, а ниже — краткая выжимка.
🔹 Уровни взаимодействия
-
В пределах Pod-а
- Контейнеры внутри Pod-а общаются через
localhost(127.0.0.1). - Поделённый сетевой namespace.
- Контейнеры внутри Pod-а общаются через
-
Между Pod-ами на одной ноде
- На каждой ноде есть
rootnetwork namespace с основным интерфейсом (eth0). - У каждого Pod-а свой namespace с интерфейсом (
eth0). - В root namespace создаются пары veth (виртуальные кабели).
- Пример:
veth123 ↔ eth0Pod-а1,veth321 ↔ eth0Pod-а2.
- Пример:
- veth-интерфейсы объединяются мостом (
cbr0/docker0). - Передача пакета:
eth0Pod → veth → bridge → veth →eth0другого Pod-а.
- На каждой ноде есть
-
Между Pod-ами на разных нодах (прямая маршрутизация, BGP)
- Используется CNI-плагин (Calico, Cilium и др.).
- Каждой ноде назначается
podCIDR. - BGP-демон на узле сообщает другим узлам о маршрутах:
- «IP Pod-а 10.48.1.5 доступен через Node1».
- Остальные узлы обновляют kernel routing table:
ip route add 10.48.1.5/32 via <Node1_IP>.
- Если Pod удаляется или мигрирует, таблицы маршрутизации обновляются автоматически.
✅ Это современный подход (Calico+BGP, Cilium и др.).
-
Между Pod-ами на разных нодах (overlay-сеть)
- Более старый подход (Flannel, старые режимы Calico).
- Пакет оборачивается в UDP и отправляется поверх основной сети.
- Шаги:
- Pod → veth → bridge (как внутри ноды).
- Пакет передаётся в CNI-плагин.
- CNI оборачивает пакет в UDP с метаданными (отправитель/получатель).
- Отправка через
eth0узла отправителя →eth0получателя. - Декапсуляция и доставка в Pod.
⚠️ Overlay-сети добавляют overhead и считаются менее производительными, чем BGP-маршрутизация.
📌 Итог:
- Pod → Pod на одной ноде — через veth + bridge.
- Pod → Pod на разных нодах — через CNI:
- либо overlay (Flannel, старый Calico),
- либо прямая маршрутизация с BGP (современный подход: Calico, Cilium).
Минусы хранения секретов в Secret-ах Kubernetes
Ответ:
-
Base64, а не шифрование
- Данные в Secret хранятся в
etcdтолько в виде base64-кодировки. - Любой, кто имеет доступ к данным, может их легко декодировать.
- Данные в Secret хранятся в
-
Доступы = полный доступ к данным
- Любой пользователь или сервис-аккаунт с правами на чтение Secret получает все данные.
- Нужны строгие
RBAC-политики.
-
Нет встроенного аудита
- Kubernetes не фиксирует, кто и когда прочитал Secret.
- Нельзя отследить утечки.
📌 Итог:
Kubernetes Secrets без дополнительной защиты — это небезопасное хранилище.
Обычно используют encryption at rest (шифрование Secret-ов в etcd) и сторонние решения (Vault, KMS).
Что можно редактировать (kubectl edit) в Pod-ах в процессе их работы, а что нельзя?
Ответ:
В Pod-е большинство параметров иммутабельны (нельзя менять после создания).
Но есть несколько исключений.
🔹 Можно редактировать
- image контейнера (основного и init-контейнера).
- tolerations (добавлять новые).
- spec.activeDeadlineSeconds.
🔹 Нельзя редактировать
- Volumes и volumeMounts.
- Порты контейнеров.
- Переменные окружения (
env). - Labels/Selectors, имя Pod-а, namespace.
- Любые поля, влияющие на сетевую конфигурацию.
📌 Итог:
Pod в Kubernetes почти неизменяем.
Можно обновить только отдельные поля (image, tolerations, activeDeadlineSeconds).
Все остальные изменения требуют пересоздания Pod-а.
С помощью какого механизма идёт или перестаёт идти трафик в Kubernetes?
Ответ:
В Kubernetes управление трафиком реализуется несколькими механизмами:
-
NetworkPolicy
- Ограничивает сетевой трафик на уровне Pod-ов (Ingress/Egress правила).
- Работает через CNI-плагин (Calico, Cilium и др.).
- Без поддержки в CNI не работает.
-
Ingress/Egress Controllers
- Ingress Controller управляет входящим HTTP/HTTPS-трафиком (маршрутизация, TLS).
- Egress Controller (или egress policies) управляет исходящим трафиком Pod-ов наружу.
-
Service Mesh (например, Istio, Linkerd)
- Добавляет уровень прокси (sidecar, чаще Envoy).
- Позволяет гибко управлять трафиком: маршрутизация, шифрование, аутентификация, трейсинг.
📌 Итог:
- NetworkPolicy → контроль сетевого уровня L3/L4.
- Ingress/Egress controllers → управление входом/выходом в кластер.
- Service Mesh → расширенный контроль и безопасность на L7.
Что такое HPA и как он работает?
Ответ:
HPA (Horizontal Pod Autoscaler) — контроллер Kubernetes, который автоматически изменяет количество Pod-ов в зависимости от нагрузки.
Работает с объектами типа Deployment, ReplicaSet, StatefulSet.
🔹 Как работает
- HPA периодически (раз в ~15 секунд) опрашивает метрики из Metrics API.
- Сравнивает текущее значение с целевым (
target). - Вычисляет рекомендуемое количество реплик по формуле:
desiredReplicas = ceil[currentReplicas × (currentMetric / targetMetric)] - Увеличивает или уменьшает число Pod-ов в пределах
minReplicasиmaxReplicas.
Чем отличается вертикальное масштабирование от горизонтального?
Ответ:
-
Горизонтальное масштабирование (HPA)
- Меняется количество Pod-ов.
- Работает через Horizontal Pod Autoscaler (HPA).
- Опирается на метрики (CPU, память, кастомные).
- Хорошо подходит для stateless-приложений (web-сервисы, API).
-
Вертикальное масштабирование (VPA)
- Меняются ресурсы Pod-а:
requestsиlimitsCPU/памяти. - Работает через Vertical Pod Autoscaler (VPA).
- Может перезапускать Pod для применения новых ресурсов.
- Подходит для stateful-приложений (БД, кэш), где реплики не всегда уместны.
- Меняются ресурсы Pod-а:
📌 Итог:
- HPA → больше/меньше Pod-ов.
- VPA → больше/меньше ресурсов у одного Pod-а.
Какая функция в Kubernetes обеспечивается Linux Capabilities?
В Kubernetes capabilities управляют тем, какие дополнительные привилегии может получить контейнер внутри Pod’а.
- По умолчанию контейнер запускается с урезанным набором capabilities (например, без
CAP_SYS_ADMIN). - Через
securityContext.capabilitiesв манифесте Pod’а можно:- добавить нужные (
add), - убрать лишние (
drop).
- добавить нужные (
Пример:
securityContext:
capabilities:
add: ["NET_BIND_SERVICE"] # позволить слушать порты <1024
drop: ["ALL"] # убрать всё лишнееТаким образом, capabilities в Kubernetes позволяют ограничивать или расширять права контейнера, избегая необходимости запускать его от root.
Последнее обновление: 3 окт. 2025 г., 14:29:20